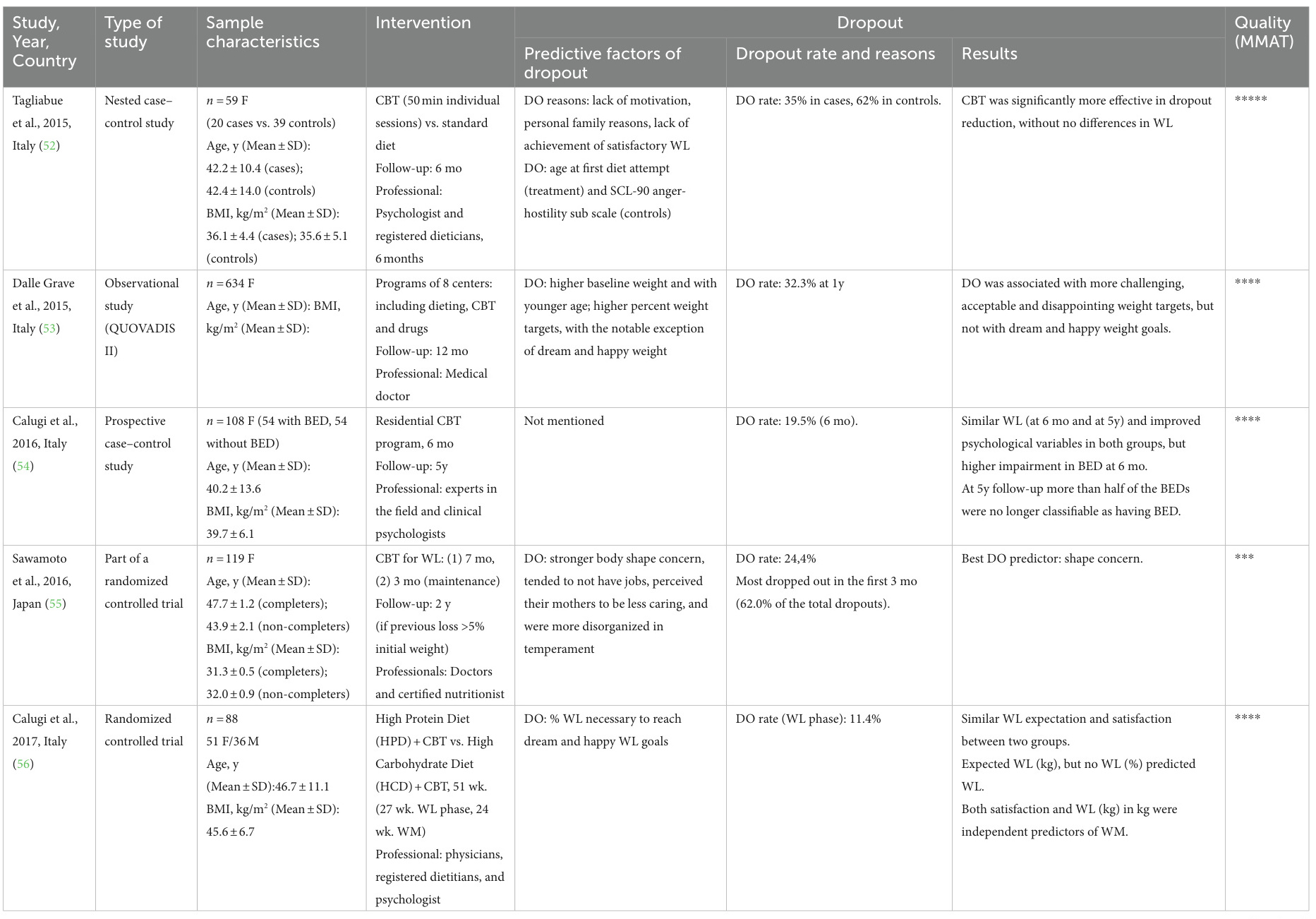
角色 + 目标:
- 角色:我是一名拥有5年经验的计算机视觉与情感计算领域的研究员,专注于面部微表情识别系统的开发与优化。
- 目标:在6个月内,研究并解决面部微表情识别系统在不同文化背景下的普适性瓶颈,提出可行的优化方案,并完成初步验证。
执行步骤:
- 文化差异分析与数据收集
• 详细行动项目:- 调研不同文化背景下面部微表情的差异(如东亚、欧美、非洲等)。
- 收集多文化背景下的面部微表情数据集(包括视频和图像)。
• 所需资源或方法: - 使用公开数据集(如CK+、MMI、SAMM)和自建数据集。
- 与跨文化心理学专家合作,获取文化差异的理论支持。
• 预期成果: - 完成文化差异分析报告。
- 建立包含至少3种文化背景的微表情数据集。
- 模型训练与优化
• 具体子任务:- 设计多文化普适性的微表情识别模型架构。
- 使用迁移学习和数据增强技术优化模型性能。
• 可衡量的目标: - 模型在跨文化数据集上的准确率达到85%以上。
- 减少文化差异导致的识别误差至少30%。
• 使用的工具或框架: - 深度学习框架(如PyTorch、TensorFlow)。
- 数据增强工具(如Albumentations)。
- 系统验证与评估
• 具体子任务:- 在不同文化背景的测试集上验证模型性能。
- 进行用户测试,收集反馈并优化系统。
• 可衡量的目标: - 系统在跨文化测试集上的F1分数达到0.8以上。
- 用户满意度评分达到4/5以上。
• 使用的工具或框架: - 评估指标(如准确率、F1分数、混淆矩阵)。
- 用户测试平台(如Qualtrics)。
限制条件:
- 强制性要求:模型必须支持至少3种文化背景的微表情识别。
- 必需的数据来源:公开数据集(如CK+、MMI)和自建数据集。
- 技术限制:模型训练时间不超过2周,推理时间不超过100ms。
- 质量标准:模型需通过严格的跨文化验证,误差率低于15%。
所需初始信息:
- 所需关键数据点:不同文化背景下的面部微表情特征差异。
- 必需的历史指标:现有微表情识别模型在跨文化数据集上的性能表现。
- 基本文档要求:文化差异分析报告、数据集描述文档、模型架构设计文档。
- 基线要求:模型在单一文化背景下的准确率需达到90%以上。
© 版权声明
文章版权归作者所有,未经允许请勿转载。